![]()
[Oct 23, 2021] Professional-Machine-Learning-Engineer Ultimate Study Guide - PracticeVCE
Ultimate Guide to Prepare Professional-Machine-Learning-Engineer Certification Exam for Google Certification in 2021
NEW QUESTION 19
A Machine Learning Specialist previously trained a logistic regression model using scikit-learn on a local machine, and the Specialist now wants to deploy it to production for inference only.
What steps should be taken to ensure Amazon SageMaker can host a model that was trained locally?
- A. Serialize the trained model so the format is compressed for deployment. Tag the Docker image with the registry hostname and upload it to Amazon S3.
- B. Serialize the trained model so the format is compressed for deployment. Build the image and upload it to Docker Hub.
- C. Build the Docker image with the inference code. Tag the Docker image with the registry hostname and upload it to Amazon ECR.
- D. Build the Docker image with the inference code. Configure Docker Hub and upload the image to Amazon ECR.
Answer: D
NEW QUESTION 20
Your team is working on an NLP research project to predict political affiliation of authors based on articles they have written. You have a large training dataset that is structured like this: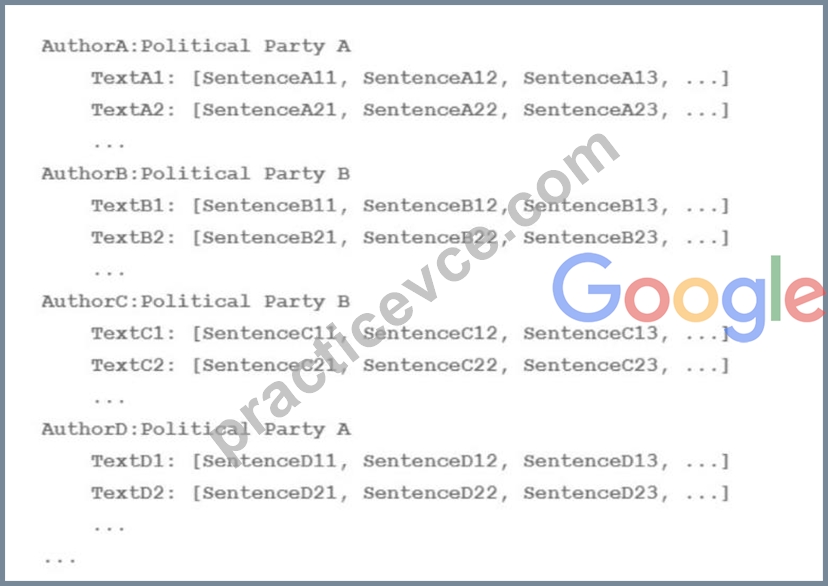
A)
B)
C)
D)
- A. Option D
- B. Option C
- C. Option A
- D. Option B
Answer: B
NEW QUESTION 21
A data scientist uses an Amazon SageMaker notebook instance to conduct data exploration and analysis. This requires certain Python packages that are not natively available on Amazon SageMaker to be installed on the notebook instance.
How can a machine learning specialist ensure that required packages are automatically available on the notebook instance for the data scientist to use?
- A. Create an Amazon SageMaker lifecycle configuration with package installation commands and assign the lifecycle configuration to the notebook instance.
- B. Use the conda package manager from within the Jupyter notebook console to apply the necessary conda packages to the default kernel of the notebook.
- C. Create a Jupyter notebook file (.ipynb) with cells containing the package installation commands to execute and place the file under the /etc/init directory of each Amazon SageMaker notebook instance.
- D. Install AWS Systems Manager Agent on the underlying Amazon EC2 instance and use Systems Manager Automation to execute the package installation commands.
Answer: C
Explanation:
Explanation
Explanation/Reference: https://towardsdatascience.com/automating-aws-sagemaker-notebooks-2dec62bc2c84
NEW QUESTION 22
A data scientist needs to identify fraudulent user accounts for a company's ecommerce platform. The company wants the ability to determine if a newly created account is associated with a previously known fraudulent user.
The data scientist is using AWS Glue to cleanse the company's application logs during ingestion.
Which strategy will allow the data scientist to identify fraudulent accounts?
- A. Create a FindMatches machine learning transform in AWS Glue.
- B. Execute the built-in FindDuplicates Amazon Athena query.
- C. Create an AWS Glue crawler to infer duplicate accounts in the source data.
- D. Search for duplicate accounts in the AWS Glue Data Catalog.
Answer: A
Explanation:
Explanation/Reference: https://docs.aws.amazon.com/glue/latest/dg/machine-learning.html
NEW QUESTION 23
You are designing an architecture with a serveress ML system to enrich customer support tickets with informative metadata before they are routed to a support agent. You need a set of models to predict ticket priority, predict ticket resolution time, and perform sentiment analysis to help agents make strategic decisions when they process support requests. Tickets are not expected to have any domain-specific terms or jargon.
The proposed architecture has the following flow:
Which endpoints should the Enrichment Cloud Functions call?
- A. 1 = Al Platform, 2 = Al Platform, 3 = AutoML Vision
- B. 1 = Al Platform, 2 = Al Platform, 3 = Cloud Natural Language API
- C. 1 = cloud Natural Language API, 2 = Al Platform, 3 = Cloud Vision API
- D. 1 = Al Platform, 2 = Al Platform, 3 = AutoML Natural Language
Answer: D
NEW QUESTION 24
Your company manages a video sharing website where users can watch and upload videos. You need to create an ML model to predict which newly uploaded videos will be the most popular so that those videos can be prioritized on your company's website.
Which result should you use to determine whether the model is successful?
- A. The model predicts 97.5% of the most popular clickbait videos measured by number of clicks.
- B. The model predicts videos as popular if the user who uploads them has over 10,000 likes.
- C. The model predicts 95% of the most popular videos measured by watch time within 30 days of being uploaded.
- D. The Pearson correlation coefficient between the log-transformed number of views after 7 days and 30 days after publication is equal to 0.
Answer: C
NEW QUESTION 25
You are working on a Neural Network-based project. The dataset provided to you has columns with different ranges. While preparing the data for model training, you discover that gradient optimization is having difficulty moving weights to a good solution. What should you do?
- A. Change the partitioning step to reduce the dimension of the test set and have a larger training set.
- B. Use feature construction to combine the strongest features.
- C. Improve the data cleaning step by removing features with missing values.
- D. Use the representation transformation (normalization) technique.
Answer: C
NEW QUESTION 26
You have trained a model on a dataset that required computationally expensive preprocessing operations. You need to execute the same preprocessing at prediction time. You deployed the model on Al Platform for high-throughput online prediction. Which architecture should you use?
- A. Validate the accuracy of the model that you trained on preprocessed data
* Create a new model that uses the raw data and is available in real time
* Deploy the new model onto Al Platform for online prediction - B. Stream incoming prediction request data into Cloud Spanner
* Create a view to abstract your preprocessing logic.
* Query the view every second for new records
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue. - C. Send incoming prediction requests to a Pub/Sub topic
* Set up a Cloud Function that is triggered when messages are published to the Pub/Sub topic.
* Implement your preprocessing logic in the Cloud Function
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue - D. Send incoming prediction requests to a Pub/Sub topic
* Transform the incoming data using a Dataflow job
* Submit a prediction request to Al Platform using the transformed data
* Write the predictions to an outbound Pub/Sub queue
Answer: C
NEW QUESTION 27
You work with a data engineering team that has developed a pipeline to clean your dataset and save it in a Cloud Storage bucket. You have created an ML model and want to use the data to refresh your model as soon as new data is available. As part of your CI/CD workflow, you want to automatically run a Kubeflow Pipelines training job on Google Kubernetes Engine (GKE). How should you architect this workflow?
- A. Use Cloud Scheduler to schedule jobs at a regular interval. For the first step of the job. check the timestamp of objects in your Cloud Storage bucket If there are no new files since the last run, abort the job.
- B. Configure a Cloud Storage trigger to send a message to a Pub/Sub topic when a new file is available in a storage bucket. Use a Pub/Sub-triggered Cloud Function to start the training job on a GKE cluster
- C. Configure your pipeline with Dataflow, which saves the files in Cloud Storage After the file is saved, start the training job on a GKE cluster
- D. Use App Engine to create a lightweight python client that continuously polls Cloud Storage for new files As soon as a file arrives, initiate the training job
Answer: B
NEW QUESTION 28
You are building a model to predict daily temperatures. You split the data randomly and then transformed the training and test datasets. Temperature data for model training is uploaded hourly. During testing, your model performed with 97% accuracy; however, after deploying to production, the model's accuracy dropped to 66%. How can you make your production model more accurate?
- A. Normalize the data for the training, and test datasets as two separate steps.
- B. Apply data transformations before splitting, and cross-validate to make sure that the transformations are applied to both the training and test sets.
- C. Split the training and test data based on time rather than a random split to avoid leakage
- D. Add more data to your test set to ensure that you have a fair distribution and sample for testing
Answer: B
NEW QUESTION 29
You are designing an ML recommendation model for shoppers on your company's ecommerce website. You will use Recommendations Al to build, test, and deploy your system. How should you develop recommendations that increase revenue while following best practices?
- A. Because it will take time to collect and record product data, use placeholder values for the product catalog to test the viability of the model.
- B. Use the "Other Products You May Like" recommendation type to increase the click-through rate
- C. Import your user events and then your product catalog to make sure you have the highest quality event stream
- D. Use the "Frequently Bought Together' recommendation type to increase the shopping cart size for each order.
Answer: D
Explanation:
Frequently bought together' recommendations aim to up-sell and cross-sell customers by providing product.
NEW QUESTION 30
Your organization's call center has asked you to develop a model that analyzes customer sentiments in each call. The call center receives over one million calls daily, and data is stored in Cloud Storage. The data collected must not leave the region in which the call originated, and no Personally Identifiable Information (Pll) can be stored or analyzed. The data science team has a third-party tool for visualization and access which requires a SQL ANSI-2011 compliant interface. You need to select components for data processing and for analytics. How should the data pipeline be designed?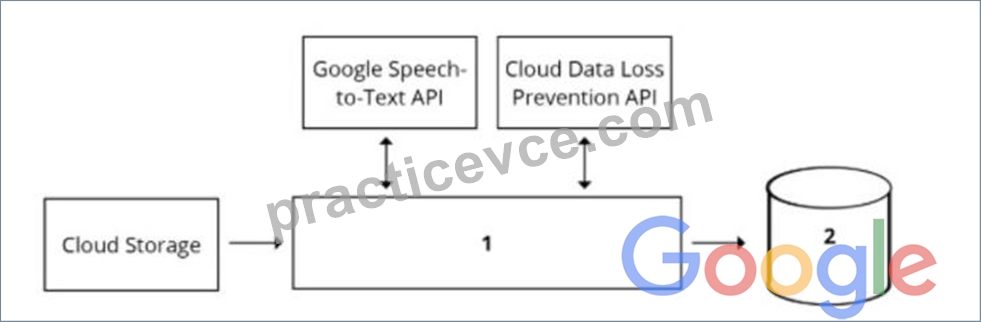
- A. 1 = Cloud Function, 2 = Cloud SQL
- B. 1 = Dataflow, 2 = BigQuery
- C. 1 = Dataflow, 2 = Cloud SQL
- D. 1 = Pub/Sub, 2 = Datastore
Answer: A
NEW QUESTION 31
A Machine Learning Specialist wants to bring a custom algorithm to Amazon SageMaker. The Specialist implements the algorithm in a Docker container supported by Amazon SageMaker.
How should the Specialist package the Docker container so that Amazon SageMaker can launch the training correctly?
- A. Configure the training program as an ENTRYPOINTnamed train
- B. Use CMD configin the Dockerfile to add the training program as a CMD of the image
- C. Modify the bash_profile file in the container and add a bashcommand to start the training program
- D. Copy the training program to directory /opt/ml/train
Answer: B
NEW QUESTION 32
A machine learning (ML) specialist wants to secure calls to the Amazon SageMaker Service API. The specialist has configured Amazon VPC with a VPC interface endpoint for the Amazon SageMaker Service API and is attempting to secure traffic from specific sets of instances and IAM users. The VPC is configured with a single public subnet.
Which combination of steps should the ML specialist take to secure the traffic? (Choose two.)
- A. Modify the security group on the endpoint network interface to restrict access to the instances.
- B. Add a SageMaker Runtime VPC endpoint interface to the VPC.
- C. Modify the ACL on the endpoint network interface to restrict access to the instances.
- D. Add a VPC endpoint policy to allow access to the IAM users.
- E. Modify the users' IAM policy to allow access to Amazon SageMaker Service API calls only.
Answer: A,D
Explanation:
Explanation/Reference: https://aws.amazon.com/blogs/machine-learning/private-package-installation-in-amazon- sagemaker-running-in-internet-free-mode/
NEW QUESTION 33
You are an ML engineer at a regulated insurance company. You are asked to develop an insurance approval model that accepts or rejects insurance applications from potential customers. What factors should you consider before building the model?
- A. Traceability, reproducibility, and explainability
- B. Federated learning, reproducibility, and explainability
- C. Redaction, reproducibility, and explainability
- D. Differential privacy federated learning, and explainability
Answer: A
NEW QUESTION 34
During batch training of a neural network, you notice that there is an oscillation in the loss. How should you adjust your model to ensure that it converges?
- A. Decrease the learning rate hyperparameter
- B. Increase the learning rate hyperparameter
- C. Decrease the size of the training batch
- D. Increase the size of the training batch
Answer: B
NEW QUESTION 35
You are building a linear regression model on BigQuery ML to predict a customer's likelihood of purchasing your company's products. Your model uses a city name variable as a key predictive component. In order to train and serve the model, your data must be organized in columns. You want to prepare your data using the least amount of coding while maintaining the predictable variables. What should you do?
- A. Use TensorFlow to create a categorical variable with a vocabulary list Create the vocabulary file, and upload it as part of your model to BigQuery ML.
- B. Use Dataprep to transform the state column using a one-hot encoding method, and make each city a column with binary values.
- C. Use Cloud Data Fusion to assign each city to a region labeled as 1, 2, 3, 4, or 5r and then use that number to represent the city in the model.
- D. Create a new view with BigQuery that does not include a column with city information
Answer: C
NEW QUESTION 36
You are training an LSTM-based model on Al Platform to summarize text using the following job submission script:
You want to ensure that training time is minimized without significantly compromising the accuracy of your model. What should you do?
- A. Modify the 'scale-tier' parameter
- B. Modify the 'learning rate' parameter
- C. Modify the 'epochs' parameter
- D. Modify the batch size' parameter
Answer: C
NEW QUESTION 37
You need to build classification workflows over several structured datasets currently stored in BigQuery. Because you will be performing the classification several times, you want to complete the following steps without writing code: exploratory data analysis, feature selection, model building, training, and hyperparameter tuning and serving. What should you do?
- A. Use Al Platform to run the classification model job configured for hyperparameter tuning
- B. Use Al Platform Notebooks to run the classification model with pandas library
- C. Configure AutoML Tables to perform the classification task
- D. Run a BigQuery ML task to perform logistic regression for the classification
Answer: B
NEW QUESTION 38
......
Google Certification Fundamentals-Professional-Machine-Learning-Engineer Exam-Practice-Dumps: https://www.practicevce.com/Google/Professional-Machine-Learning-Engineer-practice-exam-dumps.html
Use Real Professional-Machine-Learning-Engineer Dumps - Google Correct Answers: https://drive.google.com/open?id=1NV0hMpJsNulCiK0gFbGOlKIf9AILODTv